图像描述(Image Captioning)任务旨在给定一张输入图像,计算机自动生成一句或多句与该图像相关的自然语句,同时须保证生成的语句能够对图像所展示的信息(如场景、物体、人物、关系、活动等)进行正确且流畅的描述。视频描述(Video Captioning)任务则可以视为图像描述任务在时间维度上的延伸,针对的输入数据从二维平面的图像数据拓展到了包含时间维度的视频数据,而任务的核心与图像描述任务相同,都需要实现对输入数据所包含的信息进行准确且流畅的描述。图像/视频描述都是典型的多模态任务,也是实现更为复杂图像理解乃至视频理解的一个十分重要且基础的任务。图1展示了图像描述的一个例子。

图1 图像描述实例
早期的图像/视频描述算法主要包括基于检索的方法或基于模板的方法,但是两者都有很大的局限性。近年来,深度学习方法因其在计算机视觉和自然语言处理领域均取得了重大进展而占据了主导地位。当前,编码器-解码器(Encoder-Decoder)结构应用在图像/视频描述中应用非常多,其中编码器用于提取待描述图像或视频的视觉语义特征,解码器则用于将提取到的视觉语义特征逐词解码为自然语言描述序列,经典的Show and tell模型的结构如图2所示。
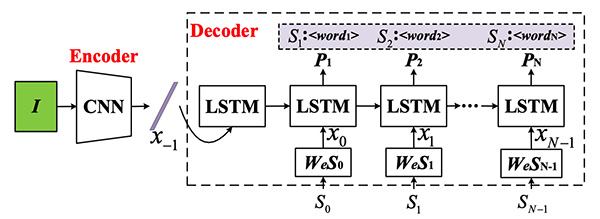
图2 Show and tell模型结构
我们在基于LRMN的图像描述模型(如图3)、模拟视觉持久性现象的图像描述模型(如图4)、基于Transformer的图像描述模型、基于图像/视频描述的盲人眼镜等方面有重要的技术创新。
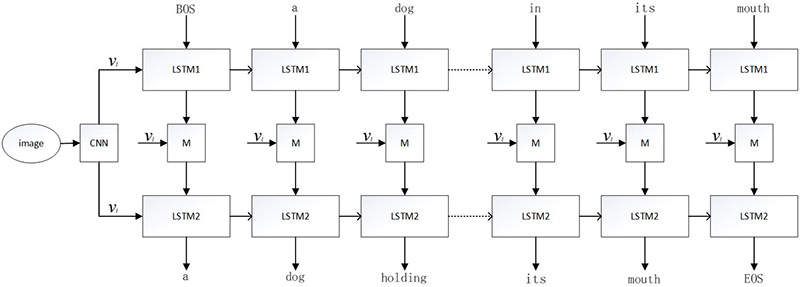
图3 基于LRMN的图像描述模型
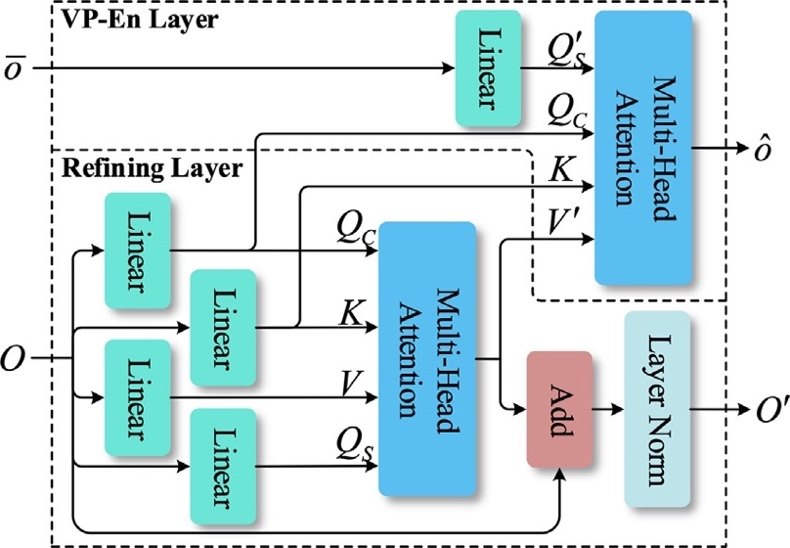
图4 模拟视觉持久性现象的图像描述模型中的编码器


 京公网安备11010802038585号
京公网安备11010802038585号


